> ## Documentation Index
> Fetch the complete documentation index at: https://dragonwingdocs.qualcomm.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Prepare a GenAI model using a Jupyter notebook
> Use Qualcomm-provided Jupyter notebooks to prepare, optimize, and deploy large language models (LLMs) on Qualcomm Dragonwing IoT platforms.
Use a Qualcomm-provided Jupyter notebook to prepare, optimize, and deploy
large language models (LLMs) on Qualcomm platforms in an interactive and
step-by-step environment. The Jupyter notebooks offer full transparency
and customization during model preparation and execution.
The following image shows the three stages and notebooks typically covered
by the Jupyter notebooks: model preparation, model conversion, and model execution.
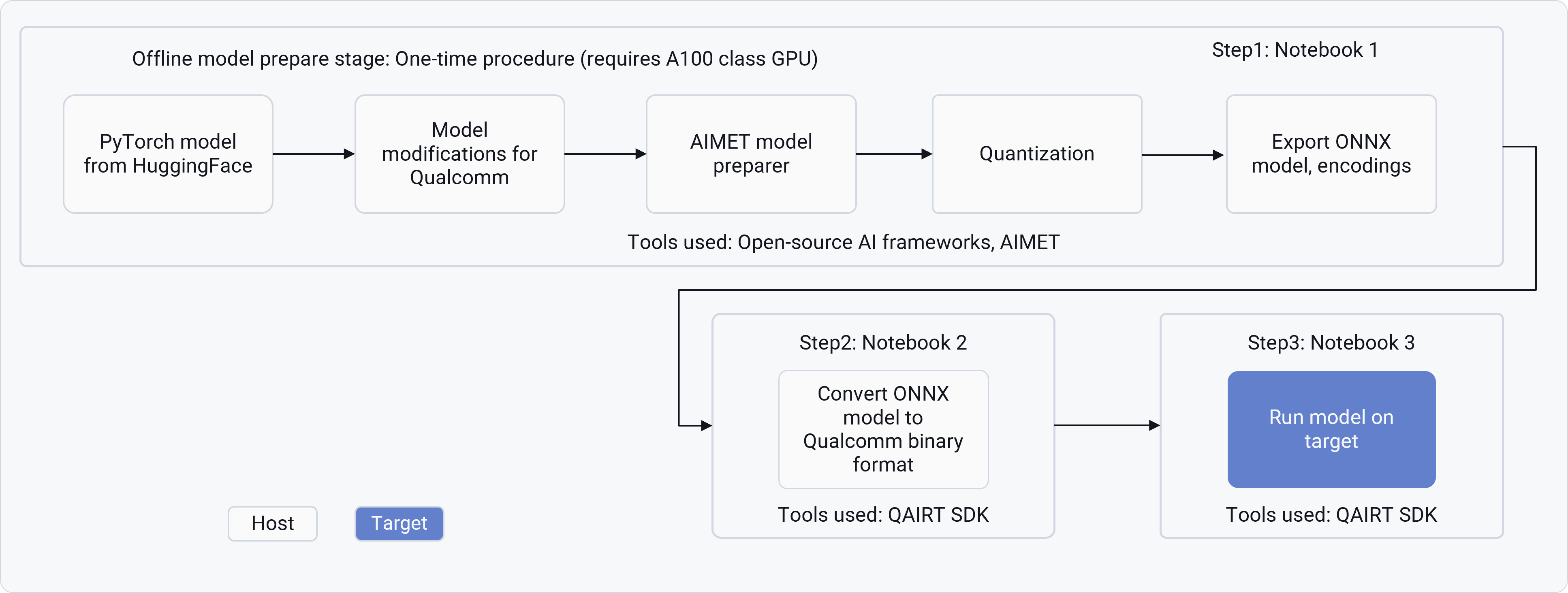 The following table summarizes the Jupyter notebook workflow for GenAI models.
This workflow is applicable for multiple categories of GenAI models, including
LLM and vision models.
| Step | Objective | Details | Artifacts generated | | |
| ---------- | ------------------------------------------------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------- | --------------- | ----------------- |
| Notebook 1 | Adapt and optimize the Hugging Face PyTorch model for Qualcomm hardware. | 1. Load base model from HuggingFace.
The following table summarizes the Jupyter notebook workflow for GenAI models.
This workflow is applicable for multiple categories of GenAI models, including
LLM and vision models.
| Step | Objective | Details | Artifacts generated | | |
| ---------- | ------------------------------------------------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------- | --------------- | ----------------- |
| Notebook 1 | Adapt and optimize the Hugging Face PyTorch model for Qualcomm hardware. | 1. Load base model from HuggingFace.
2. Apply AIMET Transformation for – Graph Optimizations, Computing encodings using techniques like Sequential MSE, and AdaRound.
3. Export optimized model to ONNX format along with AIMET encodings. AI Hub path simplifies the workflow by hosting pre-computed encodings from this step on cloud platforms. | ONNX models | AIMET encodings | Profiling reports |
| Notebook 2 | Convert ONNX models to Qualcomm AI Engine Direct (QNN) binaries | 4. Use Qualcomm AI Runtime SDK tools to generate serialized binaries from ONNX models generated in Notebook 1.
5. Create context binaries for prompt and token generation.
6. Validate model conversion with profiling metrics. | QAIRT binaries for Inference | | |
| Notebook 3 | Run the prepared model on Qualcomm-based devices. | 7. Transfer binaries and configuration files to the target device.
8. Use Genie-CLI or QAIRT runtime APIs for inference.
9. Validate performance (latency, throughput), and accuracy. | On-target model inference | | |