> ## Documentation Index
> Fetch the complete documentation index at: https://dragonwingdocs.qualcomm.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LiteRT overview
> Overview of the LiteRT framework for on-device AI inference on Qualcomm Dragonwing IoT platforms, including supported delegates and accelerators.
**LiteRT (Lite Runtime)** is an open‑source framework designed for efficient on-device deep learning inference. It provides tools to convert pretrained models (such as TensorFlow SavedModel or Keras) into the LiteRT format and optimize them for edge deployment.
On Qualcomm Linux platforms, LiteRT models can be executed either through a native LiteRT application or via the GStreamer-based Qualcomm Intelligent Multimedia SDK. The framework supports multiple hardware accelerators - including CPU, GPU, and the Qualcomm Hexagon™ Tensor Processor - through delegate. It is optimized for low latency, compact model size, and power-efficient performance on mobile, embedded, and edge devices.
The following figure shows the delegates the LiteRT framework uses to run models:
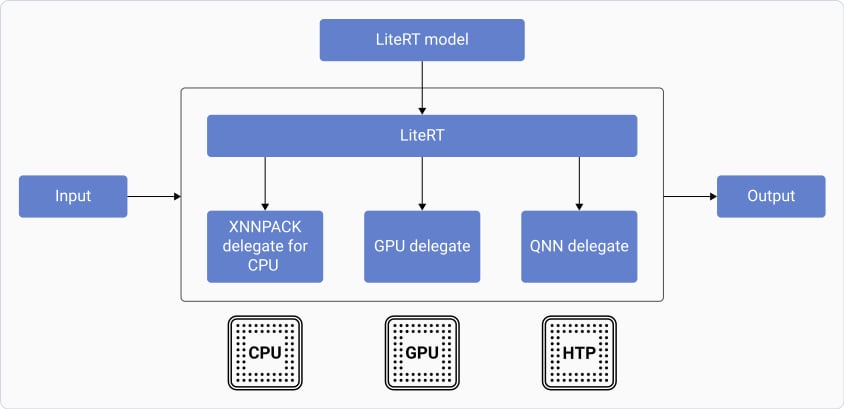 ## LiteRT on-device inference
The LiteRT on-device inference process loads the model into an interpreter, which parses the model and uses a delegate to run it.
The process includes the following steps:
1. The inference loads the LiteRT model into a LiteRT interpreter interface, which parses the model to identify the neural network operators present in it.
2. The interpreter interface is configured to run the model using a delegate.
3. The interpreter invokes model inference on the provided inputs and saves the corresponding outputs into the buffers provided to the interpreter interface.
Qualcomm supports running LiteRT models on the following accelerators using delegates:
* CPU
* Adreno GPU
* NPU
**Supported delegates and accelerators**
| Delegate | Acceleration |
| -------------------------------------------------- | ----------------- |
| XNNPACK delegate | CPU |
| GPU delegate | GPU |
| Qualcomm® AI Engine Direct delegate (QNN delegate) | CPU, GPU, and NPU |
## Next steps
For details on each delegate and how to use it, see [Supported LiteRT runtimes](../topic/run-a-litert-model).
## LiteRT on-device inference
The LiteRT on-device inference process loads the model into an interpreter, which parses the model and uses a delegate to run it.
The process includes the following steps:
1. The inference loads the LiteRT model into a LiteRT interpreter interface, which parses the model to identify the neural network operators present in it.
2. The interpreter interface is configured to run the model using a delegate.
3. The interpreter invokes model inference on the provided inputs and saves the corresponding outputs into the buffers provided to the interpreter interface.
Qualcomm supports running LiteRT models on the following accelerators using delegates:
* CPU
* Adreno GPU
* NPU
**Supported delegates and accelerators**
| Delegate | Acceleration |
| -------------------------------------------------- | ----------------- |
| XNNPACK delegate | CPU |
| GPU delegate | GPU |
| Qualcomm® AI Engine Direct delegate (QNN delegate) | CPU, GPU, and NPU |
## Next steps
For details on each delegate and how to use it, see [Supported LiteRT runtimes](../topic/run-a-litert-model).