| arithmetic\_op |
fcvAddu8 |
Matrix addition of two uint8\_t type matrixes to one uint8\_t matrix |
| fcvAddf32\_v2 | Matrix addition of two float32\_t type matrixes. |
| fcvAdds16\_v2 | Matrix addition of two int16\_t type matrixes which allows in-place operation |
| fcvSubtracts16 | Matrix substration of two uint16\_t type matrixes |
| fcvSubtractu8 | Matrix substration of two uint8\_t type matrixes |
| bilateralFilter |
fcvBilateralFilter5x5u8\_v3 |
Bilateral smoothing with 5x5 bilateral kernel |
| fcvBilateralFilter7x7u8\_v3 | Bilateral smoothing with 7x7 bilateral kernel |
| fcvBilateralFilter9x9u8\_v3 | Bilateral smoothing with 9x9 bilateral kernel |
| bilateralRecursive | fcvBilateralFilterRecursiveu8 | Here the smoothing is actually performed in gradient domain. |
| buildPyramid |
fcvPyramidAllocate\_v3 |
Allocates memory for an image pyramid. This API can be removed without notice and should only be used for testing. |
| fcvPyramidCreateu8\_v4 | Creates an image pyramid from an 8-bit unsigned (grayscale) source image. |
| fcvPyramidDelete\_v2 | Deallocates an array of fcvPyramidLevel. Can be used for any type (f32/s8/u8). |
| calcHist | fcvImageIntensityHistogram | Creates a histogram of intensities for a rectangular region of a grayscale image. |
| clusterEuclidean | fcvClusterEuclideanu8 | General function for computing cluster centers and cluster bindings |
| cvtColor |
fcvColorYCbCr420PseudoPlanarToYCbCr444PseudoPlanaru8 |
Color conversion from pseudo planar YCbCr420 to pseudo planar YCbCr444. |
| fcvColorYCbCr420PseudoPlanarToYCbCr422PseudoPlanaru8 | Color conversion from pseudo planar YCbCr420 to pseudo planar YCbCr422. |
| fcvColorYCbCr422PseudoPlanarToYCbCr444PseudoPlanaru8 | Color conversion from pseudo planar YCbCr422 to pseudo planar YCbCr444. |
| fcvColorYCbCr422PseudoPlanarToYCbCr420PseudoPlanaru8 | Color conversion from pseudo planar YCbCr422 to pseudo planar YCbCr420. |
| fcvColorYCbCr444PseudoPlanarToYCbCr422PseudoPlanaru8 | Color conversion from pseudo planar YCbCr444 to pseudo planar YCbCr422. |
| fcvColorYCbCr444PseudoPlanarToYCbCr420PseudoPlanaru8 | Color conversion from pseudo planar YCbCr444 to pseudo planar YCbCr420. |
| fcvColorRGB565ToYCbCr444PseudoPlanaru8 | Color conversion from RGB565 to pseudo-planar YCbCr444. |
| fcvColorRGB565ToYCbCr422PseudoPlanaru8 | Color conversion from RGB565 to pseudo-planar YCbCr422. |
| fcvColorRGB565ToYCbCr420PseudoPlanaru8 | Color conversion from RGB565 to pseudo-planar YCbCr420. |
| fcvColorRGB888ToYCbCr444PseudoPlanaru8 | Color conversion from RGB888 to pseudo-planar YCbCr444. |
| fcvColorRGB888ToYCbCr422PseudoPlanaru8 | Color conversion from RGB888 to pseudo-planar YCbCr422. |
| fcvColorRGB888ToYCbCr420PseudoPlanaru8 | Color conversion from RGB888 to pseudo-planar YCbCr420. |
| fcvColorYCbCr420PseudoPlanarToRGB565u8 | Color conversion from pseudo-planar YCbCr420 to RGB565. |
| fcvColorYCbCr422PseudoPlanarToRGB565u8 | Color conversion from pseudo-planar YCbCr422 to RGB565. |
| fcvColorYCbCr422PseudoPlanarToRGB888u8 | Color conversion from pseudo-planar YCbCr422 to RGB888. |
| fcvColorYCbCr422PseudoPlanarToRGBA8888u8 | Color conversion from pseudo-planar YCbCr422 to RGBA8888. |
| fcvColorYCbCr444PseudoPlanarToRGB565u8 | Color conversion from pseudo-planar YCbCr444 to RGB565. |
| fcvColorYCbCr444PseudoPlanarToRGB888u8 | Color conversion from pseudo-planar YCbCr444 to RGB888. |
| DCT | fcvDCTu8 | Performs forward discrete Cosine transform on uint8\_t pixels |
| FAST10 |
fcvCornerFast10InMaskScoreu8 |
Extracts FAST corners and scores from the image based on the mask. |
| fcvCornerFast10InMasku8 | Extracts FAST corners from the image. |
| fcvCornerFast10Scoreu8 | Extracts FAST corners and scores from the image |
| fcvCornerFast10u8 | Extracts FAST corners from the image. |
| FFT | fcvFFTu8 | Computes the 1D or 2D Fast Fourier Transform of a real valued matrix. |
| fillConvexPoly | fcvFillConvexPolyu8 | This function fills the interior of a convex polygon with the specified color. |
| filter2D |
fcvFilterCorrNxNu8 |
NxN correlation with non-separable kernel. Border values are ignored in this function. |
| fcvFilterCorrNxNu8s16 | NxN correlation with non-separable kernel. Border values are ignored in this function. |
| fcvFilterCorrNxNu8f32 | NxN correlation with non-separable kernel. Border values are ignored in this function. |
| gaussianBlur |
fcvFilterGaussian3x3u8\_v4 |
Blurs an image with 3x3 Gaussian filter with border handling scheme specified by user |
| fcvFilterGaussian5x5u8\_v3 | Blurs an image with 5x5 Gaussian filter |
| fcvFilterGaussian5x5s16\_v3 | Blurs an image with 5x5 Gaussian filter |
| fcvFilterGaussian5x5s32\_v3 | Blurs an image with 5x5 Gaussian filter |
| fcvFilterGaussian11x11u8\_v2 | Blurs an image with 11x11 Gaussian filter |
| houghLines | fcvHoughLineu8 | Performs Hough Line detection |
| iDCT | fcvIDCTs16 | Performs inverse discrete cosine transform on int16\_t coefficients |
| IFFT | fcvIFFTf32 | Computes the 1D or 2D Inverse Fast Fourier Transform of a complex valued matrix. |
| integrateImageYUV | fcvIntegrateImageYCbCr420PseudoPlanaru8 | This function calculates the integral images of a YCbCr420 image, where the input YCbCr420 has UV interleaved. |
| matmuls8s32 | fcvMatrixMultiplys8s32 | Matrix multiplication of two int8\_t type matrices |
| meanShift |
fcvMeanShiftu8 |
Applies the meanshift procedure and obtains the final converged position. Source image must be 8 bit grayscale image. |
| fcvMeanShifts32 | Applies the meanshift procedure and obtains the final converged position. Source image must be int 32bit grayscale image. |
| fcvMeanShiftf32 | Applies the meanshift procedure and obtains the final converged position. Source image must be float 32bit grayscale image. |
| Merge |
fcvChannelCombine2Planesu8 |
Combine two channels in an interleaved fashion |
| fcvChannelCombine3Planesu8 | Combine three channels in an interleaved fashion |
| fcvChannelCombine4Planesu8 | Combine four channels in an interleaved fashion |
| moments |
fcvImageMomentsu8 |
Computes weighted average (moment) of the image pixels’ intensities. Input must be of data 8-bit image. |
| fcvImageMomentss32 | Computes weighted average (moment) of the image pixels’ intensities. Input must be of data type int32\_t. |
| fcvImageMomentsf32 | Computes weighted average (moment) of the image pixels’ intensities. Input must be of data type float32\_t. |
| NormalizeLocalBox |
fcvNormalizeLocalBoxu8 |
Calculate the local subtractive and contrastive normalization of the image. |
| fcvNormalizeLocalBoxf32 | Calculate the local subtractive and contrastive normalization of the image. |
| remap | fcvRemapu8\_v2 | Applies a generic geometrical transformation to a greyscale CV\_8UC1 image. |
| remapRGBA |
fcvRemapRGBA8888BLu8 |
Applies a generic geometrical transformation to a 4-channel CV\_8UC4 image with bilinear interpolation |
| fcvRemapRGBA8888NNu8 | Applies a generic geometrical transformation to a 4-channel CV\_8UC4 image with nearest neighbor interpolation |
| resizeDownBy2 | fcvScaleDownBy2u8\_v2 | Down-scale the image by averaging each 2x2 pixel block |
| resizeDownBy4 | fcvScaleDownBy4u8\_v2 | Down-scale the image by averaging each 4x4 pixel block |
| ResizeDown |
FcvScaleDownMNu8 |
Image downscaling using MN method |
| fcvScaleDownMNInterleaveu8 | Interleaved image downscaling using MN method |
| runMSER |
fcvMserInit |
Function to initialize MSER. |
| fcvMserNN8Init | Function to initialize 8-neighbor MSER |
| fcvMserExtu8\_v3 | Function to invoke MSER with a smaller memory footprint, the (optional) output of contour bound boxes, and additional information. |
| fcvMserExtNN8u8 | Function to invoke 8-neighbor MSER, with additional outputs for each contour. |
| fcvMserNN8u8 | Function to invoke 8-neighbor MSER. |
| fcvMserRelease | Function to release MSER resources. |
| sepFilter2D |
fcvFilterCorrSepMxNu8 |
MxN correlation with separable kernel. |
| fcvFilterCorrSep9x9s16\_v2 | 9x9 FIR filter (convolution) with seperable kernel. |
| fcvFilterCorrSep11x11s16\_v2 | 11x11 FIR filter (convolution) with seperable kernel. |
| fcvFilterCorrSep13x13s16\_v2 | 13x13 correlation with separable kernel. |
| fcvFilterCorrSep15x15s16\_v2 | 15x15 correlation with separable kernel. |
| fcvFilterCorrSep17x17s16\_v2 | 17x17 correlation with separable kernel. |
| fcvFilterCorrSepNxNs16 | NxN correlation with separable kernel. |
| sobel |
fcvFilterSobel3x3u8\_v2 |
3x3 Sobel edge filter |
| fcvFilterSobel3x3u8s16 | Creates a 2D gradient image from source luminance data without normalization. Convolution with the 3x3 Sobel kernel. |
| fcvFilterSobel5x5u8s16 | Creates a 2D gradient image from source luminance data without normalization. Convolution with the 5x5 Sobel kernel. |
| fcvFilterSobel7x7u8s16 | Creates a 2D gradient image from source luminance data without normalization. Convolution with the 7x7 Sobel kernel. |
| sobelPyramid |
fcvPyramidAllocate |
Allocates memory for Pyramid |
| fcvPyramidAllocate\_v2 | Allocates memory for Pyramid |
| fcvPyramidAllocate\_v3 | Allocates memory for Pyramid |
| fcvPyramidSobelGradientCreatei8 | Creates a gradient pyramid of integer8 from an image pyramid of uint8\_t |
| fcvPyramidSobelGradientCreatei16 | Creates a gradient pyramid of int16\_t from an image pyramid of uint8\_t |
| fcvPyramidSobelGradientCreatef32 | Creates a gradient pyramid of float32 from an image pyramid of uint8\_t |
| fcvPyramidDelete | Deallocates an array of fcvPyramidLevel. Can be used for any type(f32/s8/u8). |
| fcvPyramidDelete\_v2 | Deallocates an array of fcvPyramidLevel. Can be used for any type(f32/s8/u8). |
| fcvPyramidCreatef32\_v2 | Builds an image pyramid (with stride). Memory should be deallocated using fcvPyramidDelete\_v2 |
| fcvPyramidCreateu8\_v4 | Builds a Gaussian image pyramid. |
| sobel3x3u8 | fcvImageGradientSobelPlanars8\_v2 | Creates a 2D gradient image from source luminance data using 3x3 neighborhood with Sobel kernel |
| sobel3x3u9 | fcvImageGradientSobelPlanars16\_v2 | Creates a 2D gradient image from source luminance data using 3x3 neighborhood with Sobel kernel |
| sobel3x3u10 | fcvImageGradientSobelPlanars16\_v3 | Creates a 2D gradient image from source luminance data using 3x3 neighborhood with Sobel kernel |
| sobel3x3u11 | fcvImageGradientSobelPlanarf32\_v2 | Creates a 2D gradient image from source luminance data using 3x3 neighborhood with Sobel kernel |
| sobel3x3u12 | fcvImageGradientSobelPlanarf32\_v3 | Creates a 2D gradient image from source luminance data using 3x3 neighborhood with Sobel kernel |
| split |
fcvDeinterleaveu8 |
Performe image deinterleave for unsigned byte data. |
| fcvChannelExtractu8 | Extract channel as a single uint8\_t type plane from an interleaved or multi-planar image format |
| thresholdRange | fcvFilterThresholdRangeu8\_v2 | Binarizes a grayscale image based on a pair of threshold values. |
| trackOpticalFlowLK |
fcvTrackLKOpticalFlowu8\_v3 |
Optical flow (with stride so ROI can be supported) |
| fcvTrackLKOpticalFlowu8 | Optical flow. Bitwidth optimized implementation |
| warpAffine | fcvTransformAffineClippedu8\_v3 | Applies an affine transformation on a grayscale image using a 2x3 matrix. |
| warpAffine3Plane | fcv3ChannelTransformAffineClippedBCu8 | Applies an affine transformation on a 3-color channel image using a 2x3 matrix using bicubic interpolation. |
| warpPatchAffine | fcvTransformAffineu8\_v2 | Warps the patch centered at nPos in the input image using the affine transform in nAffine |
| warpPerspective | fcvWarpPerspectiveu8\_v5 | Warps a grayscale image using the a perspective projection transformation matrix (also known as a homography). |
| warpPerspective2Plane | fcv2PlaneWarpPerspectiveu8 | Perspective warp two images using the same transformation. |
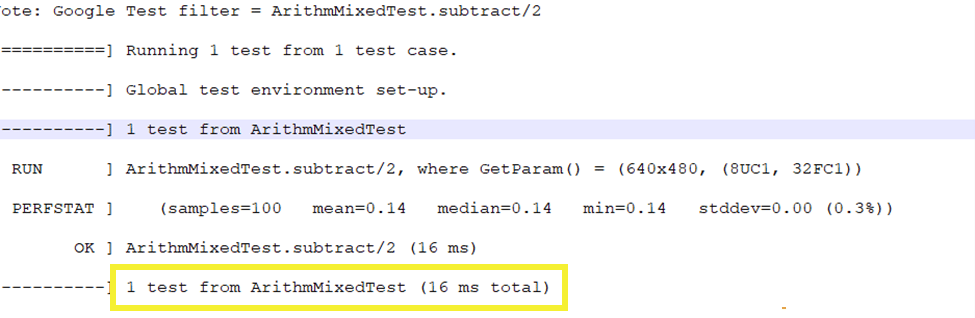 With the default OpenCV, for the same test case, the total time taken was 23 ms.
With the default OpenCV, for the same test case, the total time taken was 23 ms.
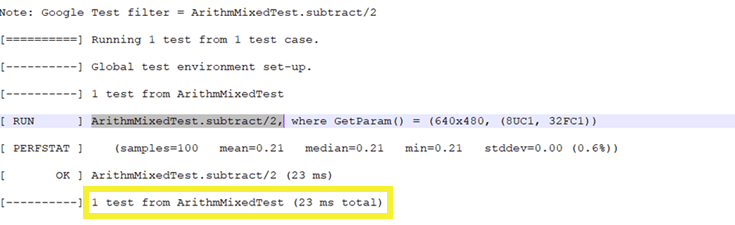 Run other test cases and compare the latency numbers between default OpenCV and FastCV accelerated OpenCV.
## **Supported OpenCV APIs and corresponding FastCV APIs**
Run other test cases and compare the latency numbers between default OpenCV and FastCV accelerated OpenCV.
## **Supported OpenCV APIs and corresponding FastCV APIs**