

Prerequisites
- Set up the QAIRT SDK on your host computer. For detailed installation and configuration instructions, see Set up Qualcomm AI Runtime SDK.
- Select the model for profiling. You can either convert and quantize a custom model using QAIRT tools or generate a quantized model through AI Hub. For detailed guidance on compiling and optimizing models, see Compile and optimize an AI model. The following instructions use the Inception V3 model from AI Hub.
- Enable Wi-Fi and SSH on the device. The device requires an internet connection to download the artifacts needed to run sample applications. If SSH and Wi-Fi are already configured, skip this step. Follow Setup an SSH connection to enable Wi-Fi and SSH on the device.
-
Ensure that you have installed the following QNN tools on the target device as part of the build.
- qnn-net-run
- qnn-throughput-net-run
- qnn-context-binary-generator
- qnn-profile-viewer
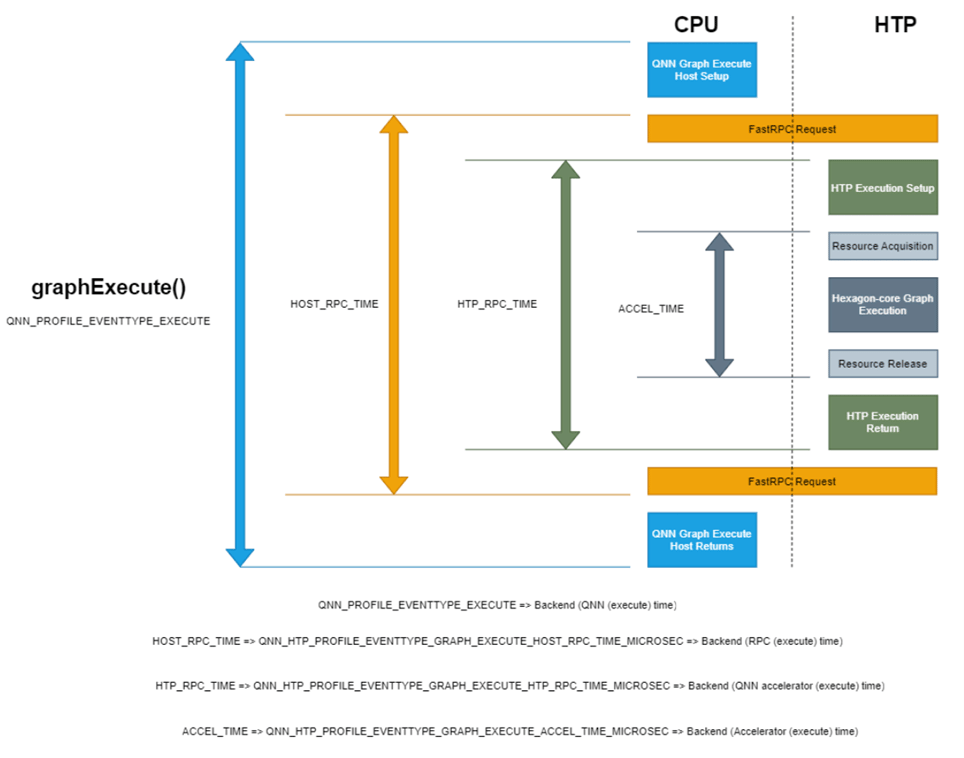
Profiling levels on HTP
The following table provides the profiling levels, their description, and configuration:| Profiling levels | Description | Configuration |
|---|---|---|
| Basic | • Total model execution time in microseconds • Use for latency measurements | --profiling_level=basic with qnn-net-run |
| Detailed | Provides basic information along with the per-operation execution time in cycles. | --profiling_level=detailed with qnn-net-run |
| Lint | • Provides per-op cycle count on main thread and background execution information. • Enables chrometrace for deeper analysis. | --profiling_level=backend with qnn-net-run and --profiling_level=linting inside backend_extension_config.json file |
| Opttrace | • Provides extremely detailed operation-level HTP execution status. • Provides HVX/HMX utilization and VTCM usage. • Use for in-depth performance bottleneck analysis. | --profiling_level=detailed and --profiling_options=optrace with qnn-net-run |
Perform Lint profile with qnn-net-run
Lint profiling provides detailed per-operation cycle counts on the main thread along with background execution information. The following steps perform lint profiling on the Inception-v3 AI Hub model. Follow these steps and replace the model with your custom model.
-
SSH into your target device:
When prompted, enter
oelinux123as the password. -
Download the quantized (w8a8) inception_v3 dlc model from AI Hub on the target
device for profiling.
-
For demonstration purposes, you can profile the model using generated input files.
Generate these input files using the following Python script tailored for the
inception_v3_quantized.dlcmodel.-
Save the following script as
generate_random_input.pyin the/etc/modelsdirectory.This script generates 10 sample input files saved in the/tmp/RandomInputsForInceptionV3Profiling/directory and aninput_list_profiling.txtfile that contains the path to each sample generated. -
Run the script on the target device:
-
Save the following script as
-
Create the
backend_extension_config_file.jsonandhtp_config.jsonfiles in the/etc/modelsdirectory of the target device to profile the model using the HTP runtime.-
backend_extension_config_file.json -
htp_config.json- Use
"dsp_arch": "v68"for Qualcomm Dragonwing™ RB3 Gen 2 - Use
"dsp_arch": "v75"for Dragonwing IQ-8275 - Use
"dsp_arch": "v73"for Dragonwing IQ-9075
- Use
-
-
Go to the
/etc/modelsdirectory and run theqnn-net-runcommand on the target device: -
Enable lint profiling by specifying
--profiling_level=backend. This step ensures that the profiling level defined in the backend-specific configuration file is applied. Theexecution_metadata.yamlandqnn-profiling-data_0.logfiles should be created in the/etc/models/output_htpdirectory. To view logs from the qnn-profiling-data_0.log file, use qnn-profile-viewer.
View lint profiling logs using qnn-profile-viewer
View the profile outputs generated at the backend profiling level by using the qnn-profile-viewer tool with the following plugins:- libQnnHtpProfilingReader.so
- libQnnChrometraceProfilingReader.so
To retrieve linting information from an inference, run qnn-profile-viewer with the The following is the sample output: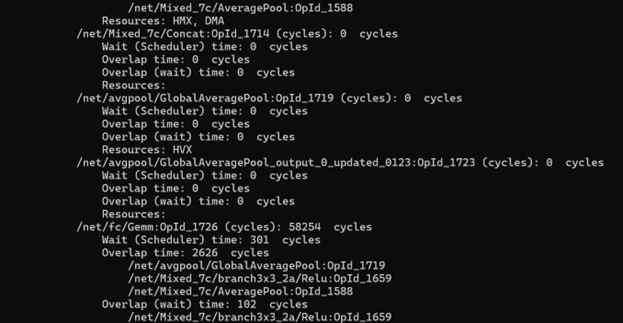
libQnnHtpProfilingReader.so plugin. This plugin provides raw output of every single run.- Cycle count: the time spent executing on the main thread.
- Wait entry: the cycles spent waiting before execution starts.
- Overlap: the cycles spent on at least one background operation while the main thread executes the current operation.
- Overlap (wait): the cycles spent on at least one background operation during the main thread’s wait period.
Every operation on the main thread has a wait period before its executed, which only begins once the previous operation has ended. This delay may be caused by scheduling issues or by waiting for background activities like HVX or DMA to finish.
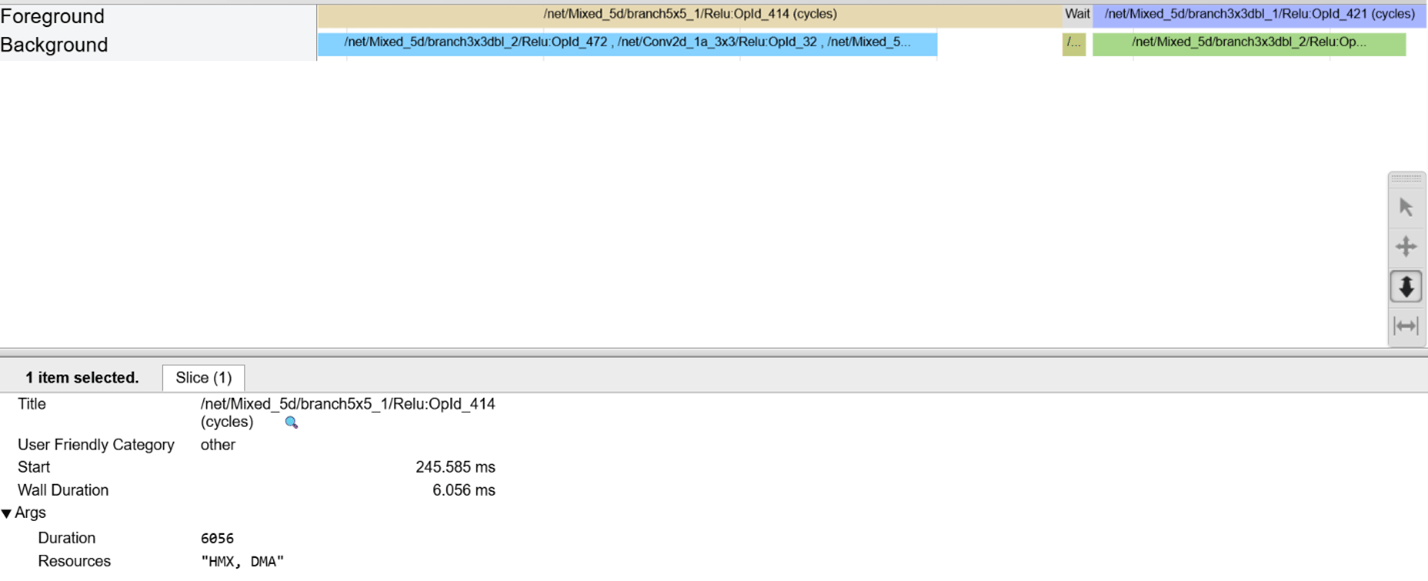
Perform advanced profiling with QNN HTP Optrace
Use QNN optrace profiling to understand detailed internal operations of QNN HTP hardware blocks. This capability helps you:- Identify problematic operations that may not be parallelized well.
- See how operations are scheduled throughout execution.
- Observe the interaction between various operators.
- Evaluate how efficiently HVX parallelism works for each operation.
Perform profiling with qnn-throughput-net-run
Use qnn-throughput-net-run for multi-threaded execution across one or more QNN backends. This profiling supports multi-threaded execution and lets you run models repeatedly for a specified duration or a set number of iterations. Use this profiling for scenarios where you need concurrent or repeated execution of multiple models for performance benchmarking.
-
SSH into your target device:
When prompted, enter
oelinux123as the password. -
On the target device, create a working directory.
-
On the target device, download the quantized (w8a8) inception_v3 dlc model from AI Hub.
-
On the target device, create the
backend_extension_config.jsonandhtp_config.jsonfiles in the/etc/modelsdirectory. These files are required to generate the context binary in the next step.- backend_extension_config.json
- htp_config.json
- Use
"dsp_arch": "v68"for Qualcomm Dragonwing™ RB3 Gen 2. - Use
"dsp_arch": "v75"for Dragonwing IQ-8275. - Use
"dsp_arch": "v73"for Dragonwing IQ-9075.
-
On the target device, generate the context binary (.bin file) using the qnn-context-binary-generator tool.
The
qnn-throughput-net-runcommand will ingest the generated context binary. -
To profile the model using
qnn-throughput-net-run, create theqtnr_config.jsonandhtp_backend.jsonfiles in the/etc/models/directory on the target device.htp_backend.json:
qtnr_config.json:
- Use
"dsp_arch":"v68"for Qualcomm Dragonwing™ RB3 Gen 2 - Use
"dsp_arch":"v75"for Dragonwing IQ-8275 - Use
"dsp_arch":"v73"for Dragonwing IQ-9075
-
To perform profiling, on the target device, run the following commands:
The profiling information is generated in the
/etc/modelsdirectory.