

- Multimedia sample applications, which show camera, video, and audio functionalities.
- AI sample applications, which show AI and machine learning (ML) capabilities.
Prerequisites
Before you begin, set up the IQ-8275 or IQ-9075 device. To use a camera, enablecamx on the device by running the following commands on the target device:
Run multimedia sample applications
The multimedia sample applications show use cases for camera, display, and video streams on the Dragonwing EVK.Multicamera streaming or encoding (Dash cam)
Description: The gst-multi-camera-example application allows you to stream from two camera sensors simultaneously. The application composes the camera feeds side by side to display on a screen or encodes and stores the video streams to files. A few use cases that need many camera inputs are dash camera or stereo camera. You can use this application as a reference and build your use case. For example, a security system where the goal is to capture a video from several cameras. You can either view it or archive it for a future review. The following figure shows the pipeline for several camera streams. For more information about the elements used in this pipeline, see pipeline flow.
gst-multi-camera-example
Try me
Try me
Run the application
Note: In the following commands, provide the necessary parameters, such as width, height, and output type. The width and height changes are applicable to the primary camera only.
Complete prerequisites
Ensure that you complete the Prerequisites.
In the terminal of the target device, select any of the following use cases and run the respective command:
Waylandsink use case: View the Waylandsink output:Encoder use case: View the encoder output:
In the terminal of the target device, run the following command to display the available help options:
Expected Output
The output is displayed on the screen and saved to a file.- If the output type is display, you can preview the stream on the display.
-
If the output type is video encoding, then the encoded files are saved at
/etc/media/cam1_vid.mp4and/etc/media/cam2_vid.mp4for camera 1 and camera 2 respectively.

Pipeline flow
The following table lists the plugins used in the multi camera streaming pipeline:| Pipeline | Description |
|---|---|
| Preview on display |
|
| Encoder dump on the device |
|
Multichannel video decode and compose (Video wall)
Description: The gst-concurrent-videoplay-composition application supports concurrent video playback for MP4 AVC (H.264) videos and performs composition on a video wall display. In the concurrent video playback and composition pipeline, four decode and composition pipelines run concurrently. For more information about the plugins used in this pipeline, see Pipeline flow.
gst-concurrent-videoplay-composition
Try me
Try me
Run the application
The following table lists the use cases that are supported through the gst-concurrent-videoplay-composition application:| Use case | Description |
|---|---|
| Video conferencing |
|
| Surveillance systems |
|
| Digital signage |
|
Complete prerequisites
Ensure that you complete the Prerequisites.
Run the use case
In the terminal of the target device, run:Command-line parameters
Examples
| Parameter | Description |
|---|---|
-c | Number of streams to decode for composition. Supported values: 2, 4, 8, 16. |
-i | Absolute path to an input video file. |
-
Concurrent playback of two sessions
-
Concurrent playback of four sessions
Expected output
The individual composed streams are tiled together to display as a unified stream.
Pipeline flow
The following table lists the plugins used to run the video wall pipeline:| Plugin | Description |
|---|---|
| filesrc |
|
| qtdemux |
|
| h264parse |
|
| v4l2h264dec |
|
| qtivcomposer |
|
| waylandsink |
|
Run AI sample applications
AI sample applications show use cases for object detection, multistream inference, and parallel inferencing on input streams from a camera, video file, or Real-Time Streaming Protocol (RTSP) stream on the Dragonwing EVK.Download and transfer AI models and labels
To run AI sample applications, download the required models and labels using one of the following methods:- Download the AI models from Qualcomm® AI Hub and labels from GitHub
-
Download the AI models and labels using the
download_artifacts.shscript On the target device, obtain thedownload_artifacts.shscript, set executable permissions, and run it to download the model, media, and label files:
| Sample application | Models required |
|---|---|
| AI object detection | yolox_quantized.tflite |
| Parallel AI inference | yolox_quantized.tflite Inception-v3 HRNetPose DeepLabV3-Plus-MobileNet |
| Multistream inference | yolox_quantized.tflite Inception-v3 |
AI object detection
Description: The gst-ai-object-detection application allows you to detect objects within images and videos. The use cases show the execution of YOLOv5, YOLOv8 and YOLOX on Qualcomm AI HW accelerator. The following figure shows the pipeline, which receives the input from a live camera feed, file, USB source, or an RTSP stream, preprocesses it, runs inferences on AI hardware. The results are either displayed on the screen, saved as an encoded MP4 file, or streamed over the RTSP server. For information about the plugins used in the pipeline flow, see Pipeline flow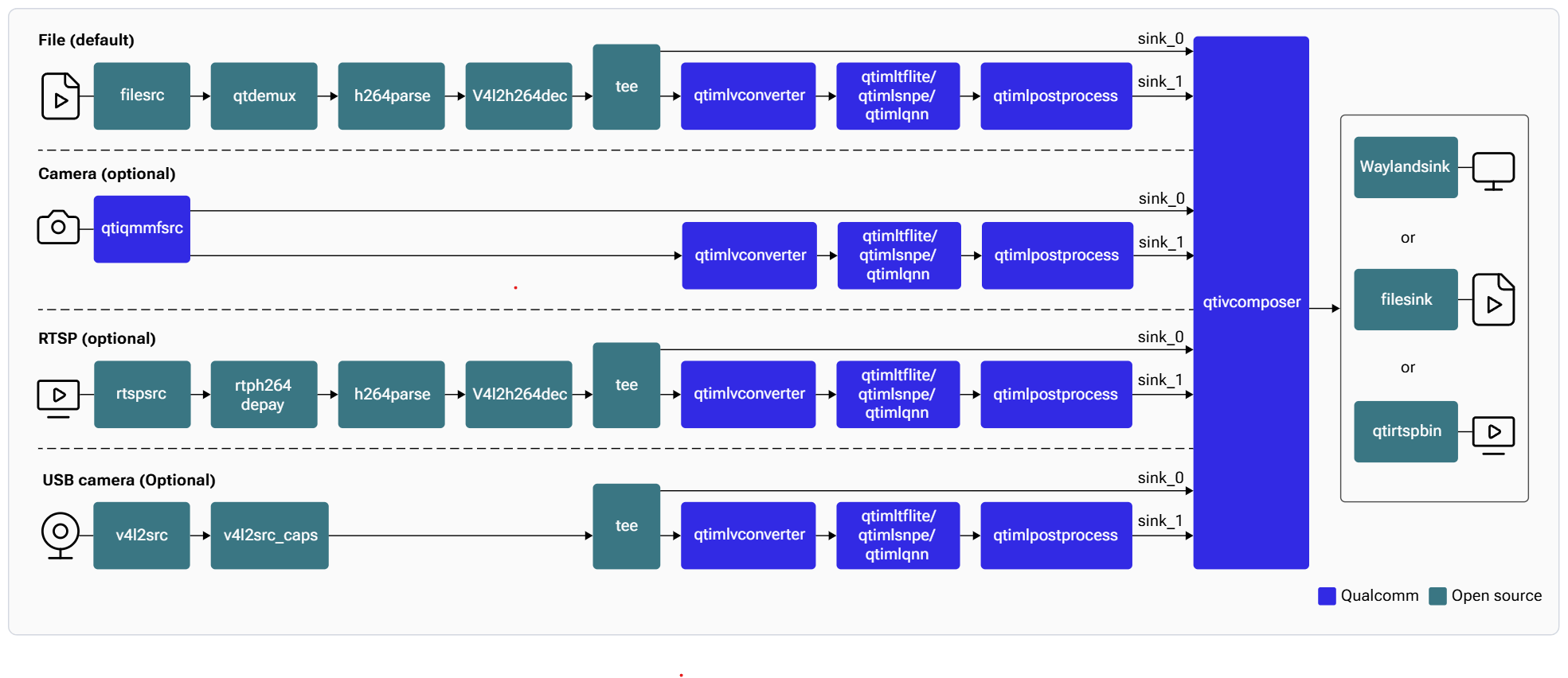
gst-ai-object-detection
Try me
Try me
When the software image includes the qticamsrc plugin, the camera framework uses it by default. If absent, the framework switches to libcamera instead. Since Config #1 lacks support for qticamsrc, the system defaults to libcamera.

Input and Output Capabilities
| Config | File src | RTSP | USB camera | MIPI camera | IMX577 camera | File output | Display | RTSP output |
|---|---|---|---|---|---|---|---|---|
| Config #1 | Yes | Yes | Yes | No | Yes | Yes | Yes | Yes |
| Config #2 | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
Sample Model and Label Files
| Runtime | Model file | Label file |
|---|---|---|
| Qualcomm Neural Processing SDK | yolonas.dlc | yolonas.json |
| LiteRT | yolov8_det_quantized.tflite / yolox_quantized.tflite | yolox.json |
| Qualcomm AI Engine Direct | yolov8_det_quantized.bin | yolov8.json |
Run the application on the target device
Download artifacts
Ensure that you download all the required artifacts to the target device.
Configurations
The gst-ai-object-detection application uses the/etc/configs/config_detection.json file. Update its properties to match your model, input stream, and output. See Config JSON Field Description for all fields.For USB camera input, set the
video-format, resolution, and framerate parameters in the config file
to match the camera capabilities, see Configure USB camera.The
snpe-tensors field applies only to the SNPE runtime. To retrieve the output tensor names for a DLC model, open the model in Netron.When using DLC models from the AI Hub, the
snpe-tensors field is optional.Available configurations
Available configurations
- Config #2
- Config #1
Camera source, LiteRT model, DSP runtime
Expected Output
Detected objects with bounding boxes and labels are overlaid on the video and displayed on the local display.Pipeline Flow
The following table lists the plugins used in the object detection pipeline:| Plugin | Description |
|---|---|
qticamsrc | • Captures the live stream from camera. • Uses tee to split the stream for inferencing. |
filesrc | • Captures the video stream using filesrc, followed by qtdemux, which demultiplexes the stream.• Uses tee to split the stream for inferencing. |
rtspsrc | • Captures the RTSP stream using rtspsrc, followed by rtph264depay for video extraction.• Uses tee to split the stream for inferencing. |
v4l2src | • Captures the live stream from USB camera. • Uses tee to split the stream for inferencing. |
h264parse | Parses the H.264 video bitstream. |
v4l2h264dec | Hardware-decodes H.264 video to raw frames. |
qtimlvconverter | 1. Receives the video stream on its sink pad. 2. Performs the following preprocessing on the stream data: • Color conversion • Scaling (up or down) • Normalization 3. Converts the preprocessed video stream to a tensor stream. The tensor stream is used for inferencing in the later stages of the pipeline. |
qtimlsnpeqtimltfliteqtimlqnn | 1. After the inference runtime receives the tensor stream on its sink pad, it runs inference using the provided model. 2. Produces a tensor stream with the inference results on its source pad. |
qtimlpostprocess | Handles inference results from any object detection model. 1. Applies a threshold to the chosen number of results. 2. Loads the YOLO (YOLOv5, YOLOv8, or YOLO-NAS) module. 3. Produces video frames with only bounding boxes that can be overlaid on objects. 4. Sends these processed frames to the sink pad of qtivcomposer. |
qtivcomposer | 1. Composes frames with contents from its sink pads. 2. Pushes the GStreamer buffers containing these composed frames to its source pad. |
waylandsink | 1. Submits the video stream received on its sink pad to Weston. 2. Weston renders the video stream on a local display. |
filesink | Receives the video stream on sink pad and saves it as an H.264-encoded MP4 file. |
qtirtspbin | 1. Serves as a network sink. 2. Transmits UDP packets to the network. |
Config JSON Field Description
| Field | Values / Description | |
|---|---|---|
ml-framework | Supported ML frameworks: • snpe (Qualcomm Neural Processing SDK)• tflite (LiteRT)• qnn (Qualcomm AI Engine Direct) | |
yolo-model-type | Supported YOLO architectures: • yolov8• yolonas• yolov5• yolox | |
runtime | Hardware runtimes: • cpu• gpu• dsp | |
Input source | Supported input sources: • camera (0=primary, 1=secondary)• file-path• rtsp-ip-port• usb-camera (set enable-usb-camera to TRUE) | |
output-ip-address | Output RTSP server IP address | |
port | Output RTSP server port | |
output-type | Supported output sinks: • waylandsink (display)• filesink (MP4 file)• rtspsink (RTSP stream) | |
snpe-tensors | ["output-tensor-name", "output-tensor-name"] | |
USB camera video-format and resolution | 1. Use one of the following video-format options:• waylandsink (display)• filesink (MP4 file)• rtspsink (RTSP stream)2. Use the following resolution fields: • width• height• framerate | |
output-file | Output filename. The default output file is output_object_detection.mp4. |
Parallel AI inference
Description: The gst-ai-parallel-inference application allows you to perform object detection, object classification, pose detection, and image segmentation on an input stream from different sources such as a camera, a file, or an RTSP network. The use cases implement the LiteRT models for object detection, image segmentation, classification, and pose detection. The following figure shows the pipeline, which receives input streams from a camera, file, or an RTSP stream, performs the parallel inferencing for the four use cases, and displays the results side by side on the screen.This application isn’t supported in
Config #1 for the QLI 2.0 release
because CPU runtime is not supported.
gst-ai-parallel-inference
Try me
Try me
Input and Output Capabilities
| Config | File src | RTSP | USB camera | MIPI camera | File output | Display | RTSP output |
|---|---|---|---|---|---|---|---|
| Config #2 | Yes | Yes | No | Yes | No | Yes | No |
Sample Model and Label Files
| Runtime | Model file | Label file |
|---|---|---|
| LiteRT | detection: yolox_quantized.tfliteclassification: inception_v3_quantized.tflitesegmentation: deeplabv3_plus_mobilenet_quantized.tflitepose: hrnet_pose_quantized.tflite | detection: yolox.jsonclassification: classification.jsonsegmentation: deeplabv3_resnet50.jsonpose: hrnet_pose.json, hrnet_settings.json |
Run the application on the target device
Download artifacts
Ensure that you download all the required artifacts to the target device.
Configurations
The gst-ai-parallel-inference application uses the/etc/configs/config-parallel-inference.json file. Update its properties to match your model, input stream, and output. See Config JSON Field Description for all fields.For QCS6490, if
file-path and rtsp-ip-port are not present in the configuration file, then the camera input is selected.Available configurations
Available configurations
- Config #2
File source, LiteRT model, DSP runtime
Expected Output
After performing the four parallel inferences, the results are displayed side by side on the screen.
Pipeline Flow
The following table lists the plugins used in the metadata parser pipeline:| Plugin | Description |
|---|---|
qticamsrc | • Captures the live stream from the camera. • Uses tee to split the stream for inferencing. |
filesrc | • Captures the video stream using filesrc.• Followed by qtdemux, which demultiplexes the stream.• Uses tee to split the stream for inferencing. |
rtspsrc | • Captures the RTSP stream using rtspsrc.• Followed by rtph264depay for video extraction.• Uses tee to split the stream for inferencing. |
h264parse | Parses the H.264 video. |
v4l2h264dec | Decodes the video. |
qtimlvconverter | 1. Receives the video stream on its sink pad. 2. Performs the following preprocessing on the stream data when the model expects floating-point values as input: • Color conversion • Scaling (up or down) • Normalization 3. The tensor stream is used for inferencing in the later stages of the pipeline. |
qtimltflite | • After the inference runtime receives the tensor stream on its sink pad, it runs the inference. • Produces a tensor stream with the inference results on its source pad. |
qtimlpostprocess — detection | a. Receives the inference tensors from the object detection model. b. Converts the inference tensors on its sink pad into formats such as video or text that the multimedia plugins can process later. c. Applies the threshold to the chosen number of results. d. Loads the corresponding modules for detection models. In this use case, qtimlpostprocess does the following:• Loads the YOLOv8 submodule. • Produces results as structures of text. • Sends them to the sink pad of qtimetamux. |
qtimlpostprocess — classification | a. Receives the inference tensors from the classification model. b. Converts the inference tensors on its sink pad into formats such as video or text that the multimedia plugins can process later. c. Applies the threshold to the chosen number of results. d. Loads the corresponding modules for classification models. In this use case, qtimlpostprocess does the following:• Loads the submodule of the model. • Produces results as video frames with classification labels. • Sends them to the sink pad of qtivcomposer. |
qtimlpostprocess — segmentation | a. Receives the inference tensors on its sink pad. b. Converts the inference tensors into video formats that the multimedia plugins can process later. c. Produces the semantic segmentations for the frame. d. Loads the corresponding modules for the segmentation models. In this use case, qtimlpostprocess does the following:• Loads the deeplab-argmax submodule. • Produces video frames with segmentation masks. • Sends them to the sink pad of qtivcomposer. |
qtimlpostprocess — pose | a. Receives the inference tensors on its sink pad. b. Converts the inference tensors into video formats that the multimedia plugins can process later. c. Applies the threshold to the chosen number of results. d. Loads the corresponding modules for various pose estimation models. In this use case, qtimlpostprocess does the following:• Loads the HRNet module. • Produces results as video frames with poses drawn. • Sends them to the sink pad of qtivcomposer. |
qtivcomposer | 1. Composes frames with contents from its sink pads. 2. Pushes the GStreamer buffers containing these composed frames to its source pad. |
waylandsink | 1. Submits the video stream received on its sink pad to Weston. 2. Weston renders the video stream on a local display. |
Config JSON Field Description
| Field | Values/Description |
|---|---|
Input source | Use one of the following input sources: • camera: Primary (0) or secondary (1).• file-path: The directory path to the video file.• rtsp-ip-port: The address of the RTSP stream: rtsp://<ip>:<port>/<stream> |
Models and labels | • detection-model: The path to the detection model.• detection-labels: The path to the detection label.• pose-model: The path to the pose model.• pose-labels: The path to the pose labels.• segmentation-model: The path to the segmentation model.• segmentation-labels: The path to the segmentation labels.• classification-model: The path to the classification model.• classification-labels: The path to the classification labels. |
Multistream inference
Description: The gst-ai-multistream-inference application shows AI inference (object detection and classification) on up to 32 input streams coming from camera, file, or RTSP stream. The following figure shows the pipeline, which receives several input streams, preprocesses them, runs AI inferences, combines the streams, and merges them all into a single video output. The maximum number of input streams supported on each SoC as verified on 1080P and 720P are follows:- QCS6490–8
- Dragonwing IQ-8275–16
-
Dragonwing IQ-9075–32
The output is displayed on an HDMI display, saved as an H.264 encoded MP4 file, or converted into an RTSP stream.This application isn’t supported in
Config #1for theQLI 2.0release because CPU runtime is not supported.

gst-ai-multistream-inference
Try me
Try me
Input and Output Capabilities
| Config | File src | RTSP | USB camera | MIPI camera | File output | Display | RTSP output |
|---|---|---|---|---|---|---|---|
| Config #2 | Yes | Yes | No | Yes | Yes | Yes | Yes |
Sample Model and Label Files
| Runtime | Model file | Label file |
|---|---|---|
| LiteRT | detection: yolox_quantized.tfliteclassification: inception_v3_quantized.tflite | detection: yolox.jsonclassification: classification.json |
Run the application on the target device
Download artifacts
Ensure that you complete the
Prerequisites. This downloads all required artifacts to the target device.Configurations
The gst-ai-multistream-inference application uses the/etc/configs/config-multistream-inference.json file. Update its properties to match your model, input stream, and output. See Config JSON Field Description for all fields.If a drop in performance is observed, you can use YOLOv8 LiteRT model. For YOLOv8 export instructions, see Prerequisites.
Available configurations
Available configurations
- Config #2
Object Detection on 8 H.264 file inputs, LiteRT model, DSP runtime
Expected Output

Pipeline Flow
The following table lists the plugins used in the metadata parser pipeline:| Plugin | Description |
|---|---|
qticamsrc | • Captures the live stream from camera. • Uses tee to split the stream for inferencing. |
filesrc | • Captures the video stream using filesrc, followed by qtdemux, which demultiplexes the stream.• Uses tee to split the stream for inferencing. |
rtspsrc | • Captures the RTSP stream using rtspsrc, followed by rtph264depay for video extraction.• Uses tee to split the stream for inferencing. |
h264parse | • Parses the H.264 video. |
v4l2h264dec | • Decodes the video. |
qtimlvconverter | 1. Receives the video stream on its sink pad. 2. Performs the following preprocessing on the stream data. This preprocessing is done when the model expects floating-point values as input: • Color conversion • Scaling (up or down) • Normalization 3. Converts the preprocessed video stream to a tensor stream on its source pad. The tensor stream is used for inferencing in the later stages of the pipeline. |
qtimltflite | 1. After the inference runtime receives the tensor stream on its sink pad, it runs the inference. 2. Produces a tensor stream with the inference results on its source pad. |
qtimlpostprocess | Handles the inference results from any object detection, classification, pose detection, and segmentation model. Detection use case: • Applies a threshold to the chosen number of results. • Loads the YOLOv8 module. • Produces video frames with only bounding boxes that can be overlaid on objects, sending them to the sink pad of qtivcomposer.Classification use case: • Applies the threshold to the chosen number of results. • Loads the MobileNet-softmax module. • Produces results as video frames with classification labels, sending them to the sink pad of qtivcomposer. |
qtivcomposer | 1. Composes frames with contents from its sink pads. 2. Pushes the GStreamer buffers containing these composed frames to its source pad. |
waylandsink | 1. waylandsink submits the video stream received on its sink pad to Weston.2. Weston renders the video stream on a local display. |
filesink | 1. Receives the video stream on its sink pad. 2. Saves the stream as a H.264-encoded MP4 file. |
qtirtspbin | 1. Serves as a network sink. 2. Transmits UDP packets to the network. |
Config JSON Field Description
| Field | Values / Description |
|---|---|
Input source | Use one of the following input sources: • num-camera: The number of inputs from the camera.• camera: The input camera if num-camera=1.• input-file-path: The directory path to the video file.• input-rtsp-path: The address of the RTSP stream: rtsp://<ip>:<port>/<stream> |
input-type | The video encoding type for file and RTSP input: • H.264• H.265 |
Output | Use one of the following outputs: • output-file-path: The directory path to save the output file.• output-ip-address: The IP address of the device on which the RTSP stream can be played.• output-port-number: The port number of the device on which the RTSP stream can be played.• output-display: The connected display device for preview. Select 1 to enable this option. |