

- How will you prepare your model? Convert, quantize, compile, or fine-tune it for the target hardware.
- How will you run inference? The runtime or integration path that executes the model on the device.
Choose your journey
Use the flowchart below to find the path that fits your application. It walks you through whether you already have a model, how to prepare it (purple), and how to run inference (blue), then links you to the right guide. Every highlighted box is clickable.On-device generative AI availability depends on your Qualcomm Linux release. See the GenAI workflow page for the current support status.
AI architecture
The following diagram illustrates the AI application development architecture on Qualcomm platforms.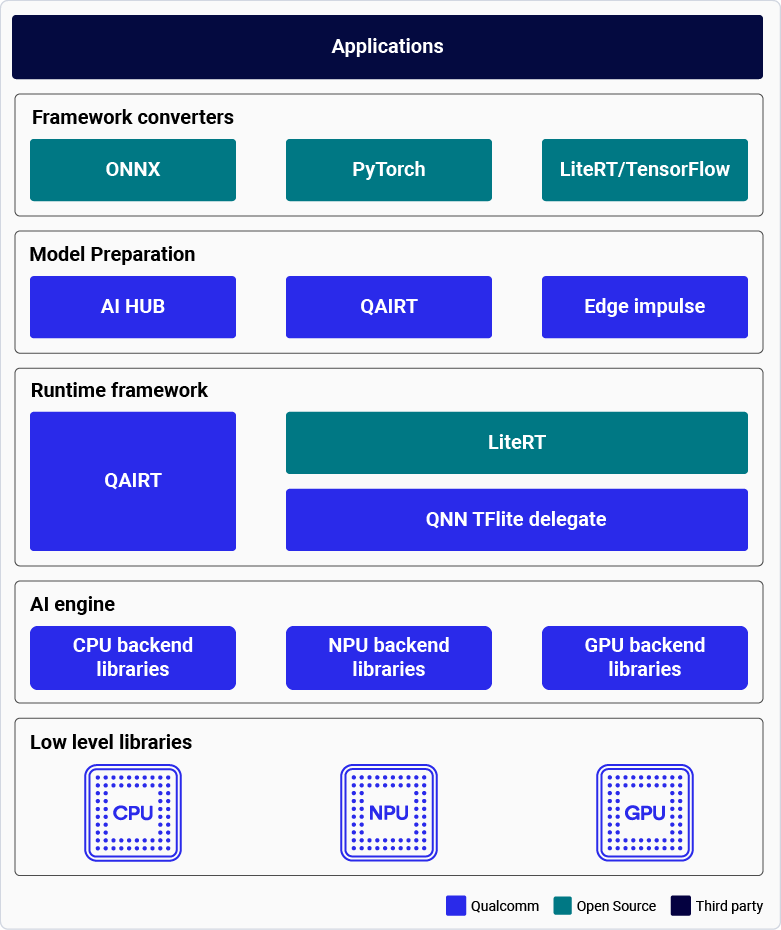
Prepare your model
Before a model runs efficiently on Qualcomm hardware, it is converted to an executable format and, for the Hexagon NPU (HTP), quantized to a supported precision. (LiteRT models are an exception: they run directly through the AI Engine Direct delegate.) Choose the preparation tool that matches your starting point.| Tool | Use it to | Output |
|---|---|---|
| Qualcomm AI Hub | Download a preoptimized model, or bring your own model (BYOM) and have QAIRT compile, convert, and quantize it in the cloud for your target chipset, with no local toolchain required. | Ready-to-run LiteRT or Qualcomm AI Engine Direct model |
| Qualcomm AI Runtime SDK (QAIRT) | The local alternative to AI Hub BYOM: convert, quantize, and compile models from TensorFlow, PyTorch, LiteRT, or ONNX yourself. Integrates AI Engine Direct and the Neural Processing SDK. | Quantized model / compiled context binary |
| Qualcomm AI Model Efficiency Toolkit (AIMET) | Recover accuracy lost during quantization using post-training quantization (PTQ) and quantization-aware training (QAT). | Higher-accuracy quantized model |
| Edge Impulse | Build, train, or fine-tune models from your own audio, image, and sensor data. | Trained model in your chosen format |
Run inference
After your model is prepared, choose how to execute it on the device. The runtime you pick depends on your language, model format, and whether you are building a full camera/video pipeline.| Runtime / integration | Best for |
|---|---|
| LiteRT | High-performance on-device inference from Python or C++, using Qualcomm AI Engine Direct delegates. |
| QAIRT SDK C++ APIs | Low-level C++ control over model execution and the inference backend. |
| Qualcomm Intelligent Multimedia SDK (IM SDK) | High-performance camera, video, and vision pipelines that combine capture, preprocessing, inference, and rendering, with zero-copy buffers and GPU pre/post-processing. |
| Qualcomm® GenAI Inference Engine (Genie) | Running and orchestrating on-device generative AI (LLMs, multimodal) workflows. |
Building a robotics application? The Qualcomm® Intelligent Robotics (QIR) SDK adds ROS-based modules and hardware-accelerated nodes on top of these runtimes.
AI hardware
Qualcomm platforms include the following hardware accelerators for AI inference:- Qualcomm Kryo™ CPU — High-performance CPU with best-in-class power efficiency.
- Qualcomm Adreno™ GPU: Balanced power and performance for AI workloads, accelerated with OpenCL kernels. Also used for model pre- and post-processing (for example, the IM SDK runs resize, color conversion, and overlay on the GPU).
- Qualcomm Hexagon™ Tensor Processor (HTP): Also known as NPU/DSP/HMX. Optimized for low-power, high-performance AI inference. For best performance, quantize pretrained models to a supported precision.