benchmark_model tool to measure model execution performance on hardware using delegates. This tool is installed on the target device along with other LiteRT artifacts.
The tool measures and reports the following performance metrics:
- Initialization time
- Inference time (warm-up and steady state)
- Memory usage during initialization
- Overall memory usage
Prerequisites
Before running the benchmark, ensure you have the following:- An Ubuntu 22.04 host computer
- A Qualcomm development kit
Set up model files
- Download the sample model, label files, and a test image:
-
On the host computer, download and extract the MobileNet model archives:
-
On the target device, create the artifacts directory:
-
From the host computer, copy the model, image, and label files to the device:
-
On the target device, set up the GPU libraries:
Benchmark on CPU
Thelabel_image sample application is cross-compiled with the LiteRT library and installed on the target device. The source code is available on the TensorFlow GitHub repository.
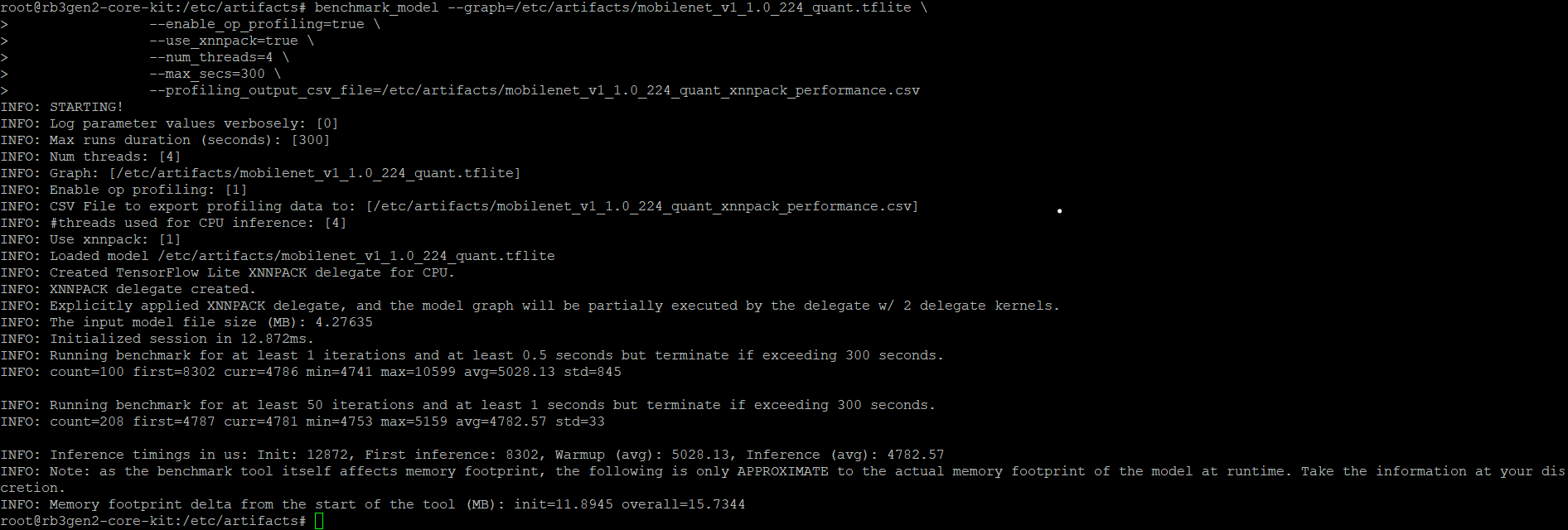
To benchmark using the XNNPACK delegate on the CPU:
Benchmark on GPU
To benchmark using the GPU delegate: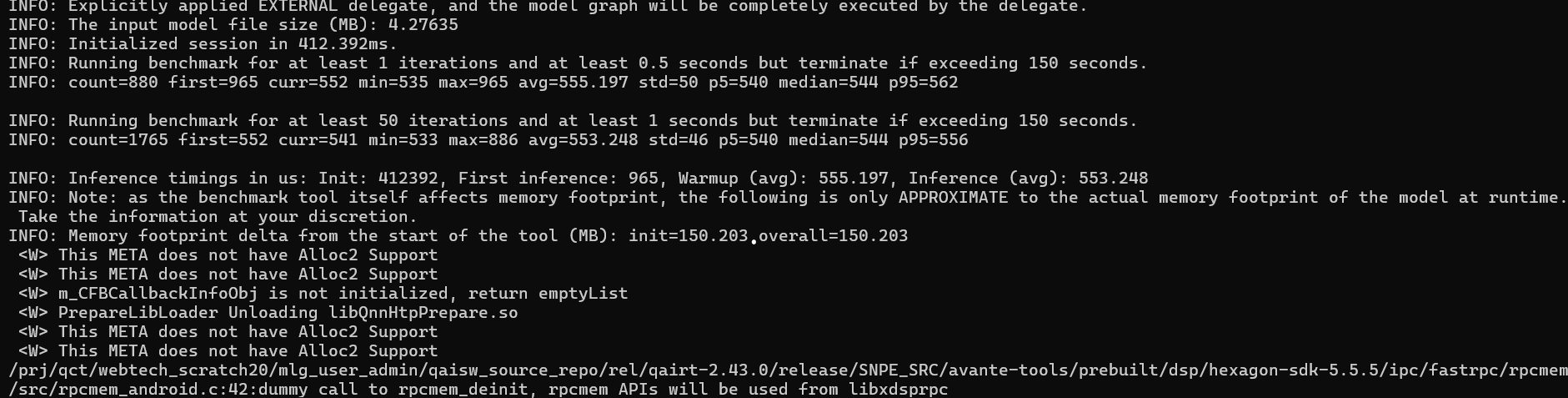
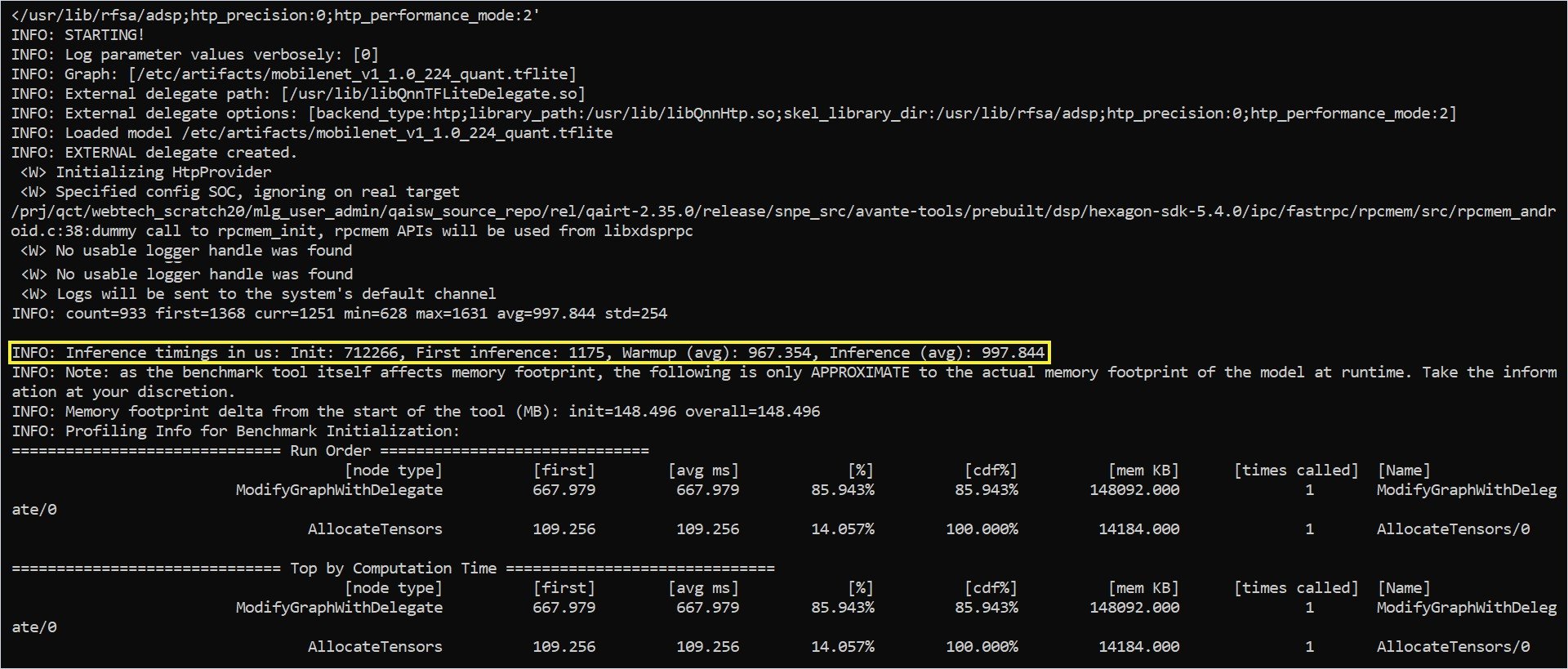
Benchmark on NPU using the QAIRT delegate
The Qualcomm AI Runtime delegate uses the Qualcomm AI Runtime API and its backends to accelerate models on the Adreno GPU and the Hexagon Tensor Processor. To use the QAIRT external delegate, ensure the following libraries are available on the device:libQnnTFLiteDelegate.so— QNN delegate library- Libraries from the Qualcomm AI Engine Direct SDK
libQnnGpu.so— Run the QNN delegate on the GPUlibQnnHtp.so— Run the QNN delegate on the Hexagon Tensor ProcessorlibQnnDsp.so— Run the QNN delegate on the DSP
- QCS6490/QCS5430, IQ-9075, and QCS8275
- IQ-615
- Delegate creation status
- Average inference time on the hardware using the delegate
- Memory footprint of the model execution