

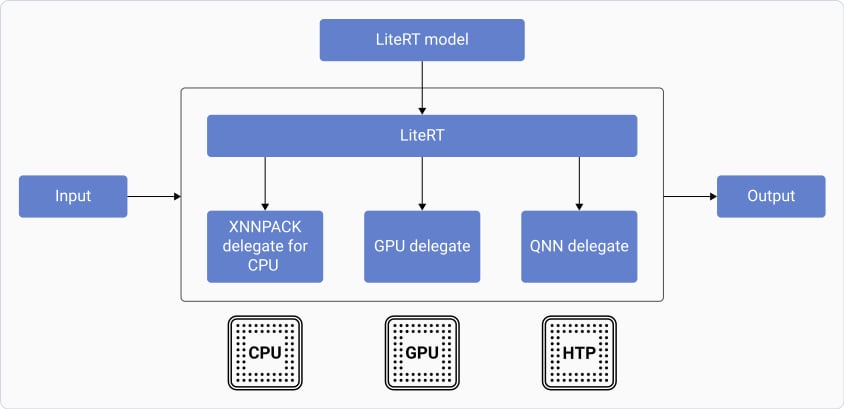
LiteRT on-device inference
The LiteRT on-device inference process loads the model into an interpreter, which parses the model and uses a delegate to run it. The process includes the following steps:- The inference loads the LiteRT model into a LiteRT interpreter interface, which parses the model to identify the neural network operators present in it.
- The interpreter interface is configured to run the model using a delegate.
- The interpreter invokes model inference on the provided inputs and saves the corresponding outputs into the buffers provided to the interpreter interface.
- CPU
- Adreno GPU
- NPU
| Delegate | Acceleration |
|---|---|
| XNNPACK delegate | CPU |
| GPU delegate | GPU |
| Qualcomm® AI Engine Direct delegate (QNN delegate) | CPU, GPU, and NPU |