

label_image sample application, the LiteRT C++ APIs, or the Qualcomm IM SDK gst-ai-classification pipeline.
Before deploying, ensure you have completed the prerequisites and model setup.
Deploy as a native application
Thelabel_image sample application is part of the TensorFlow repository and is cross-compiled with the LiteRT library and installed on the target device. It loads a classification LiteRT model and performs inference on an image using a delegate.
Run on CPU using the XNNPACK delegate:
Deploy as a C++ application
The following figure shows the steps involved in creating a C++ application to run a LiteRT model:
Load a LiteRT model
A LiteRT model is a FlatBuffers file containing model operators, weights, and biases. Use the following API to load a model for inference:Create a LiteRT interpreter
The interpreter configures model execution on a chosen delegate and allocates memory for forward propagation:Prepare the model with a delegate
The following example creates the XNNPACK delegate for running a LiteRT model on the Arm® CPU:Prepare input/output buffers
Before running inference, preprocess the input data (such as camera frames) to match the model’s expected format. Common preprocessing steps include:- Resizing the input image to the resolution expected by the model
- Normalization
- Mean subtraction
Run inference
Use theInvoke() API to run inference. After completion, parse the output tensors from the interpreter:
Deploy with the Qualcomm IM SDK
Thegst-ai-classification sample application uses the Qualcomm IM SDK plugins to run a LiteRT classification model on Qualcomm development kits with hardware acceleration.
The pipeline receives a video stream from a camera, performs preprocessing, runs inference on the AI hardware, and displays the results:
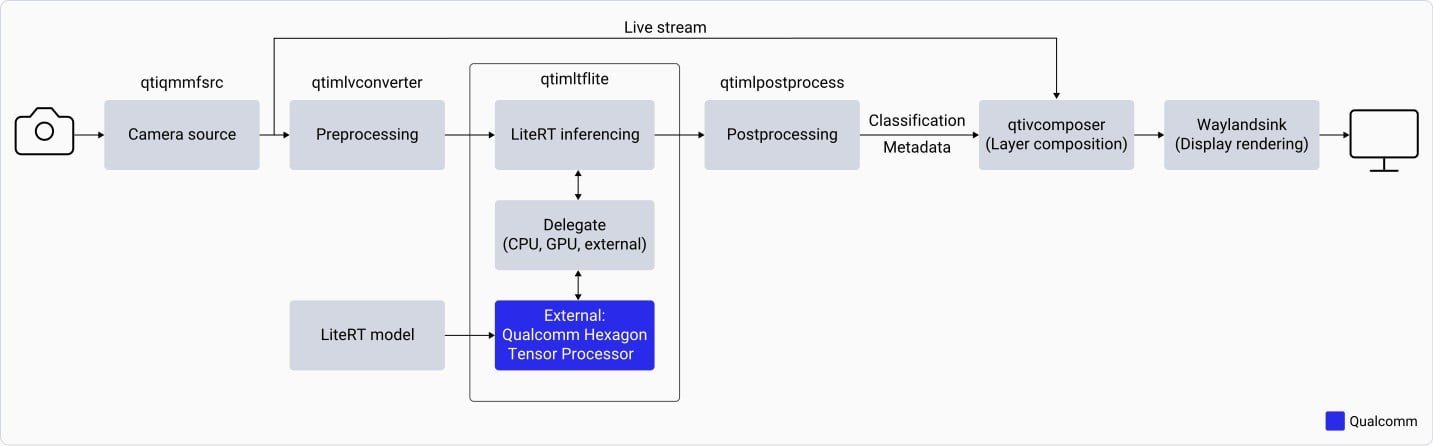
gst-ai-classification application:
- Opens the IMX577 camera at a specified resolution and frame rate (for example, 1080p at 30 fps).
- Preprocesses each camera frame — downscales to 224×224 and normalizes based on model requirements.
- Loads the LiteRT classification model and runs inference using the
qtimltfliteplugin. - Extracts the label with the highest predicted probability from the output tensor.
- Overlays the inference result on the original camera frame and displays it on the connected monitor.
Download the model and label files
- Go to Qualcomm AI Hub and download the Inception-v3 quantized model.
-
Download the label file:
-
On the target device, create the required directories:
-
Copy the model and label files to the device:
Run the sample application
-
Sign in to the target device using SSH:
-
Edit the
/etc/configs/config_classification.jsonconfiguration file: -
Copy a video file to
/etc/media/video.mp4on the device. -
Run the classification sample application:
To stop the application, press
Ctrl+C.