

Overview
qtimldemux is a GStreamer plugin designed for batch-oriented AI inference pipelines, where multiple independent inputs are processed together in a single inference execution. Its primary role is to demultiplex batched output tensors and restore them as per-input results, so downstream elements can continue processing each input independently. This is essential in multi-stream and batched AI workflows, where batched execution improves hardware utilization, but downstream stages must continue to operate on a per-stream or per-sample basis.
qtimldemux commonly operates in conjunction with qtibatch. In such pipelines, qtibatch performs input aggregation before inference, and qtimldemux performs output demultiplexing after inference. This pairing allows pipelines to benefit from batched model execution without losing per-input result alignment.
qtibatchaggregates multiple input streams or buffers into a single batched inputqtimldemuxsplits the resulting batched output back into per-input tensors or results
Hierarchy
GObjectGstObject
GstElement
qtimldemux
Pad Templates
sink
| Capabilities | |
|---|---|
neural-network/tensors | format: { INT8, UINT8, INT32, UINT32, FLOAT16, FLOAT32 } |
| Availability: Always | |
| Direction: sink |
src
| Capabilities | |
|---|---|
neural-network/tensors | format: { INT8, UINT8, INT32, UINT32, FLOAT16, FLOAT32 } |
| Availability: On request | |
| Direction: source |
Why Batch Inference Requires Output Demultiplexing
Many machine learning models are designed to process multiple inputs in a single inference execution. This execution model is commonly referred to as batch inference. In batch-based models, the input tensor includes an explicit batch dimension, allowing the model to process a fixed number of independent inputs together rather than one input at a time. Batch inference is widely used because it:- improves hardware utilization
- reduces per-input inference overhead
- increases accelerator efficiency through better scheduling
- matches the fixed input shape requirements of many deployed models
Constructing Batched Input
Before inference can be executed, multiple independent inputs must be collected and combined into a single batched input. In a streaming pipeline, this usually involves:- receiving data from multiple logical input sources, such as separate streams or sensors
- selecting one input unit from each source, such as a video frame or audio buffer
- assembling those inputs into a single batched representation that matches the model input shape
Batched Output Representation
When inference is executed on a batched input, the model produces batched output tensors. These output tensors contain the inference results for all inputs in the batch, organized according to the same batch structure used at the input. At this stage:- the inference results for all inputs are grouped into a single output
- each result is identified only by its position in the batch
- the original stream-level or input-level separation is no longer explicit
Why Demultiplexing Is Needed
Most downstream elements do not operate on batched results. Post-processing, metadata generation, visualization, tracking, and application logic typically expect results on a per-input basis. These stages usually require:- inference output corresponding to a single logical input
- correct association between each result and its originating stream or sample
- independent downstream processing for each input
Role of Demultiplexing
The demultiplexing stage restores the logical separation that existed before batch inference. It:- extracts the result corresponding to each batch element
- re-establishes the mapping between inference results and their original inputs
- allows downstream elements to continue operating in a per-stream or per-sample manner
Usage
Multi stream batched mode AI Inference
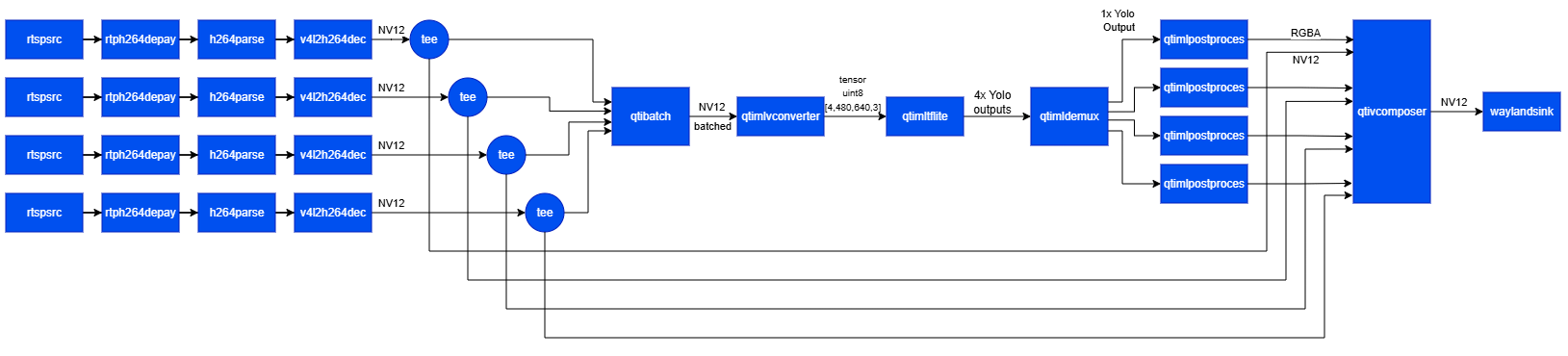
This example demonstrates a four-stream batched inference pipeline using video files as input. Four file sources feed the same video intoqtibatch, which aggregates frames into a single batched input. qtimlvconverter prepares the batched tensors, and qtimltflite performs batched inference. qtimldemux then restores per-stream outputs so that post-processing can run independently on each stream. The resulting metadata is combined with the corresponding video streams by qtivcomposer, and the final 2×2 composition is displayed using waylandsink.
Download Required Files
| File | Download | Save as |
|---|---|---|
| Yolov8 Detection W8A8 Batch 4 model | Export from Qualcomm AI Hub | yolov8_det_w8a8_batch_4.tflite |
| Detection labels | yolov8.json | yolov8.json |
| Sample video | Input video | Draw_1080p_180s_30FPS.mp4 |